Introducción.
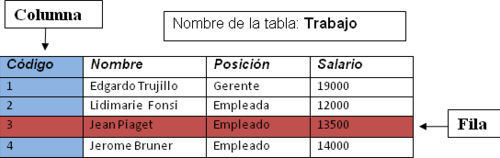
Una Base de Datos es una colección de archivos, datos, información; ordenada, organizada, y relacionada, con la finalidad de permitir el manejo de la información para su procesamiento. Cada uno de los archivos representan una colección de registros y cada registro está compuesto de una colección de campos. Cada uno de los campos de cada registro permite llevar información de alguna característica o atributo de alguna entidad del mundo real.
El DBMS es un conjunto de programas que se encargan de manejar la creación y todos los accesos a las bases de datos. Se compone de un Lenguaje de Definición de Datos (DDL: Data Definition Languaje), de un Lenguaje de Manipulación de Datos (DML: Data Manipulation Languaje), y de un Lenguaje de Consulta (SQL: Structured Query Languaje).
Sistema de Administración de Base de Datos (DBMS).
Es el nivel de software que provee el acceso a la información a un alto nivel de abstracción. En lugar de manipular archivos, registros, índices, el programa de aplicación opera en términos de clientes, cuentas, saldos, etc.
Acceso a la Base de Datos

La secuencia conceptual de operaciones que ocurren para accesar cierta información que contiene una base de datos es la siguiente:
- El usuario solicita cierta información contenida en la base de datos.
- El DBMS intercepta este requerimiento y lo interpreta.
- DBMS realiza las operaciones necesarias para accesar y/o actualizar la información solicitada
Para ver el gráfico seleccione la opción "Descargar" del menú superior
Proceso para Accesar Información de Bases de Datos.
Unidad I. Funciones del Administrador de la Base de Datos.
- Conceptos Generales.
Administrador de la Base de Datos. Es la persona encargada de definir y controlar las bases de datos corporativas, además proporciona asesoría a los desarrolladores, usuarios y ejecutivos que la requieran. Es la persona o equipo de personas profesionales responsables del control y manejo del sistema de base de datos, generalmente tiene(n) experiencia en DBMS, diseño de bases de datos, Sistemas operativos, comunicación de datos, hardware y programación.
Un Administrador de Base de Datos de tiempo completo normalmente tiene aptitudes técnicas para el manejo del sistema en cuestión a demás, son cualidades deseables nociones de administración, manejo de personal e incluso un cierto grado de diplomacia. La característica más importante que debe poseer es un conocimiento profundo de las políticas y normas de la empresa, así como el criterio de la empresa para aplicarlas en un momento dado. La responsabilidad general del DBA es facilitar el desarrollo y el uso de la Base de Datos dentro de las guías de acción definidas por la administración de los datos.
El Administrador de Bases de Datos es responsable primordialmente de:
- Administrar la estructura de la Base de Datos.
- Administrar la actividad de los datos.
- Administrar el Sistema Manejador de Base de Datos.
- Establecer el Diccionario de Datos.
- Asegurar la confiabilidad de la Base de Datos.
- Confirmar la seguridad de la Base de Datos.
Administrar la estructura de la Base de Datos.
Esta responsabilidad incluye participar en el diseño inicial de la base de datos y su puesta en practica así como controlar, y administrar sus requerimientos, ayudando a evaluar alternativas, incluyendo los DBMS a utilizar y ayudando en el diseño general de la bases de datos. En los casos de grandes aplicaciones de tipo organizacional, el DBA es un gerente que supervisa el trabajo del personal de diseño de la BD.
Una vez diseñada las bases de datos, es puesta en práctica utilizando productos del DBMS, procediéndose entonces a la creación de los datos (captura inicial). El DBA participa en el desarrollo de procedimientos y controles para asegurar la calidad y la alta integridad de la BD.
Los requerimientos de los usuarios van modificándose, estos encuentran nuevas formas o métodos para lograr sus objetivos; la tecnología de la BD se va modificando y los fabricantes del DBMS actualizan sus productos. Todas las modificaciones en las estructuras o procedimientos de BD requieren de una cuidadosa administración.